その他の手法について
ロジスティック回帰分析
0〜1の範囲をとる値を予測します.予測値は0〜1の範囲を出ません.
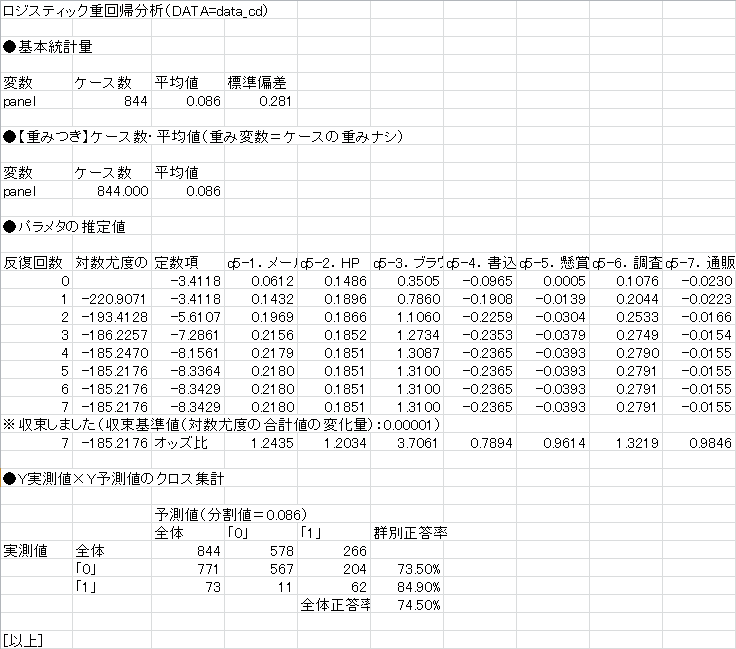
こうして予測式を作れば,同じ式が当てはまることが想定される場合,あらた標本について同じ質問をすれば,計算から従属変数の値を予測することができます.ある変数が1単位増えたとき,(他の変数を固定した場合に)従属変数が1になる率がどのくらい高まるかは「オッズ比」を見ます.
なお,この例から従属変数の値を予測する式を作ると,以下のようになります.
y = 1/1+exp{-(-8.3429+0.2180*x1+0.1851*x2+1.3100*x3-0.2365*x4-0.0393*x5+0.2791*x6-0.0155*x7)}
共分散構造分析
データに基づいて構成概念の当てはまりや構造を検証します.
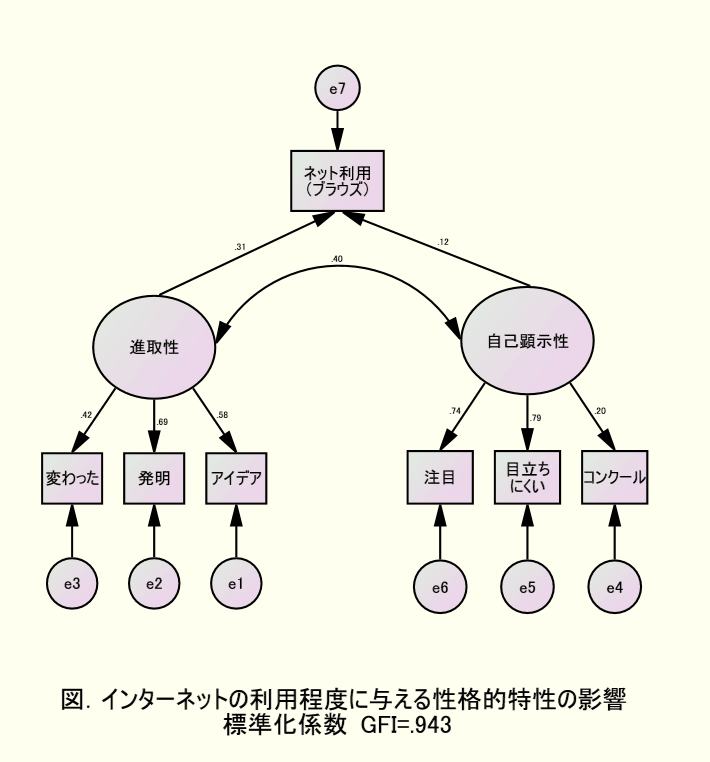
なお,ある程度の回答者数が必要など,常にいかなるモデルも検証できるというわけではありません.予測より解釈を考え,基本的に多重指標モデルを考えます.必要に応じ多母集団の同時分析を行います.
行列散布図/行列分割表
多項選択肢の回答データから計算した相関行列を使用する場合,散布図行列を出力してもあまり意味がない場合があります.たとえば下記は3択の設問の場合です.
この場合,クロス集計表を並べるほうが読み取ることのできる情報は増えます(3値しかとらない変数を間隔尺度以上とみなして良いかという問題はあります).上記と同じデータをクロス表(値は全体%.赤みが強いほど%が大きい)を並べる形で出すと下記.必要に応じこうした出力を作成します.
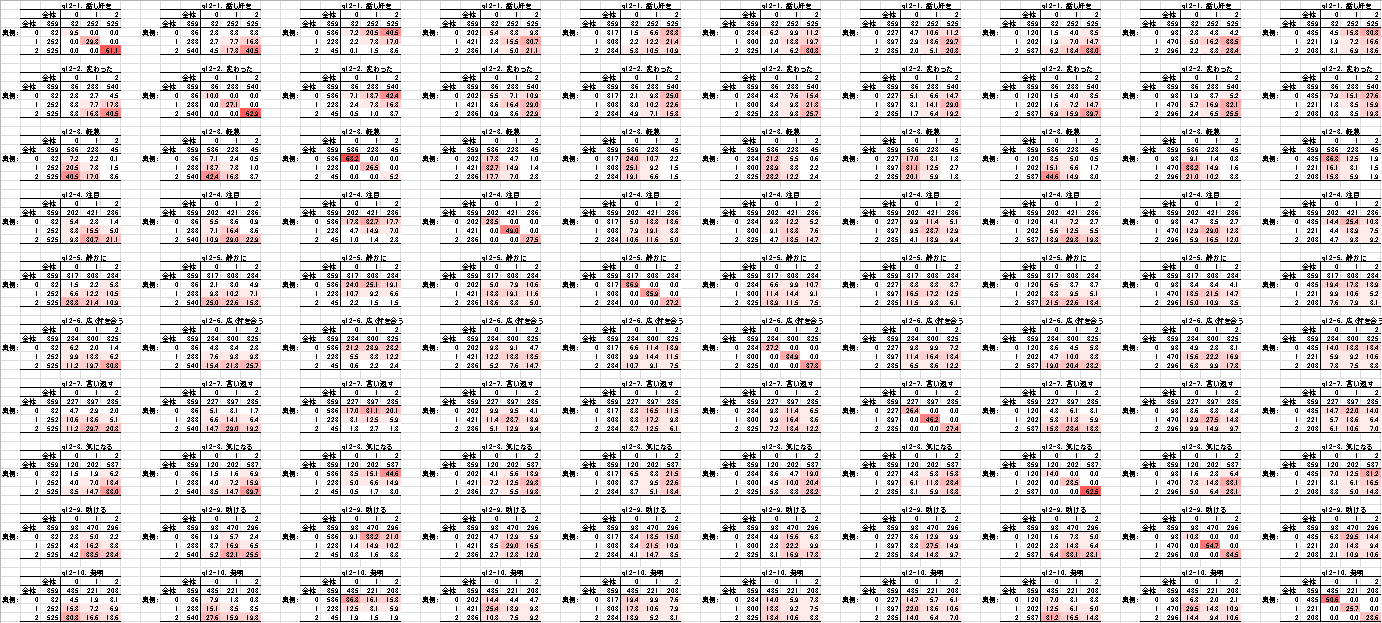
相関係数行列(分散共分散行列)を使った分析では,線形の関係がない変数どうしを使うと,分析結果がデータをうまく説明しないことがしばしばおこります.多くの場合,こうした出力を参照しておくほうが安全です.
選好回帰(重回帰分析を使う場合)
AHP(Analytic Hierarchy Process:階層分析法)
プロペンシティスコア/傾向スコア/propensity score
コウホート分析(重回帰分析を使う場合)
Twitter データのテキストマイニング
Twitter データのテキストマイニングについてはそれぞれ以下ごらんください.
ご注意ください
- 当サイトの記述内容や公開資料などによってもたらされるいかなる結果に対しても,制作者は一切の責任を負いません.
- 引用はご自由にどうぞ.著作者表記は特に記載のない場合“データエクスプローリング”あるいは“DATAEXPLORING”としてください.
- ご連絡をいただきましても,返信をお約束するものではありません.ご了承をお願いいたします.
戻る
(C)2001-2015 DATAEXPLORING